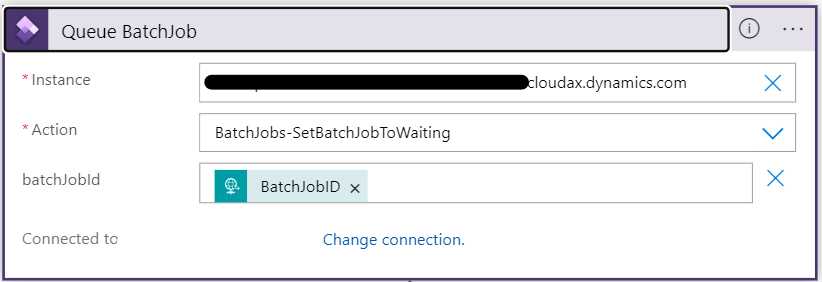
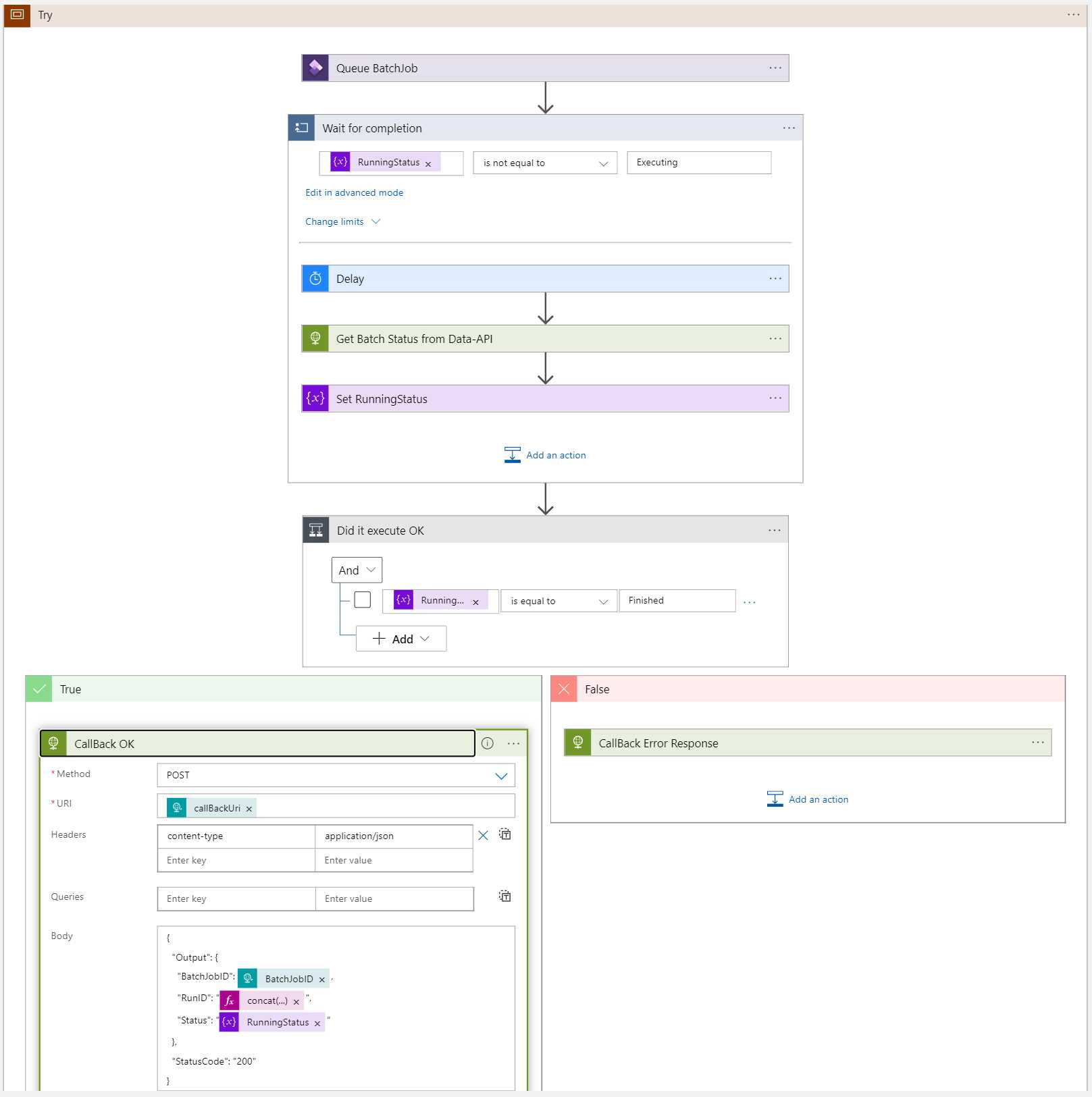
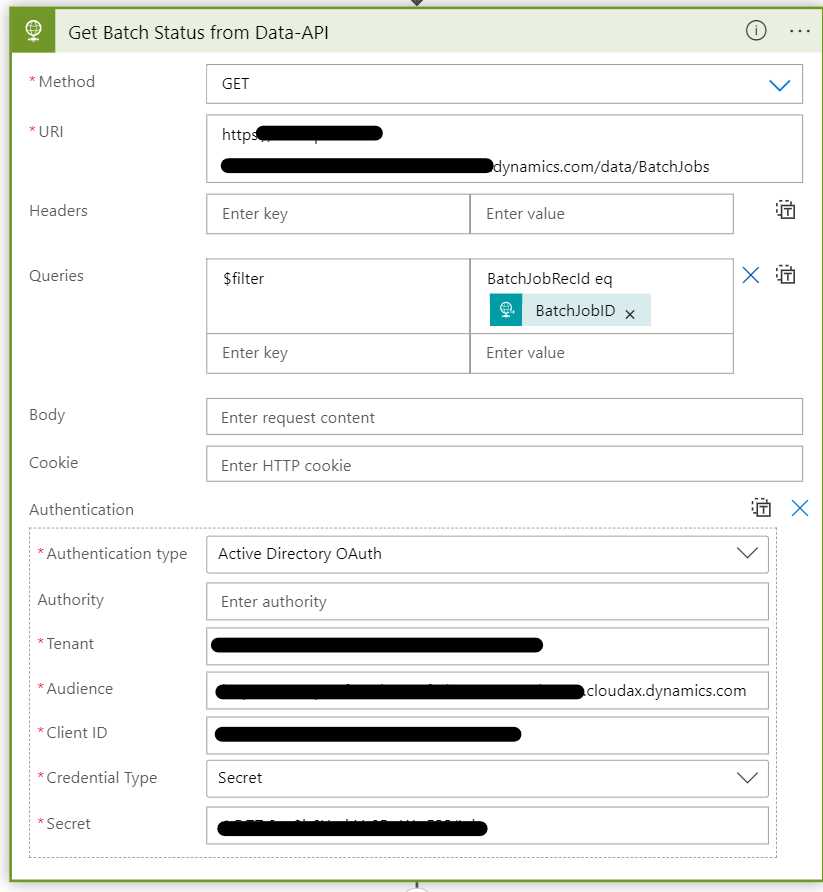
The F&O Rest APIs
I decided to rewrite the article(s) from Microsoft about how to communicate with the Rest APIs in D365. The reason being that almost all documentation is written from the perspective of a person who knows a lot about D365 and how it works. If you are like me; you just want the data. I will walk you thru how to setup authentication, how to authenticate and where to find data.
This is probably a bit lengthy, so feel free to use the ToC to read about the thing you need to know.
Setting up authentication
This is done in three parts: Create an application registration (identity), assign access rights, and register in D365.
Create an application registration
This is very similar to how you usually handle autheticating to Azure APIs. Setup an App Registration with a client secret. I made a Just make it work post on this.
Assign Access Rights
This is easier than you might think. In the left menu click API Permissions.
Then find and click + Add a Permission.
In the flyout menu to the right scroll down and find the Dynamics ERP option.

Click on Delegated permissions and select all options. Yeah this seems like too much but according to the official documentation it is ok.
Register in D365
This is straight forward. Just follow the official documentation:
- In Finance and Operations apps, go to System administration > Setup > Azure Active Directory applications.
- Select New.
- Fill in the fields for the new record:
- In the Client Id field, enter the application ID that you registered in Azure AD.
- In the Name field, enter a name for the application.
- In the User ID field, select an appropriate service account user ID. For this example, we have selected the Admin user. However, as a better practice, you should provision a dedicated service account that has the correct permissions for the operations that must be performed.
- When you have finished, select Save.
Authenticating
In order to authenticate you need to get an OAUTH token, just like with any Microsoft API. However, there are some important differences.
I will be using Postman to create and issue calls.
Preparing Postman
Your life will be much better if you use variables rather than hard coded values. Create the following:
Global
Environment
| Variable name |
Value |
Comment |
| D365clientId |
Client ID |
The client Id of the application registration created earlier. |
| D365clientSecret |
Client Secret |
The client secret of the application registration created earlier. |
| D365InstanceUrl |
D365 URL |
The whole URL of the D365 instance you want to communicate with. Includes https at the start of the string. Example: https://myinstancename.testperhaps.dynamics.com |
Collection
| Variable name |
Value |
Comment |
| c_bearertoken |
Empty |
Will contain the OAUTH token after authentication |
Setting the URL
You need to create a new POST with this URL https://login.microsoftonline.com/{{G_AzureTenantId}}/oauth2/v2.0/token
This is so Azure AD knows where to route the call, and you need to point it to your Azure tenant.
Create the body
- Select the “Form-Data” option.
- Select Bulk Edit (to the right)
- Paste the following into the window
Client_Id:{{D365clientId}}
Client_Secret:{{D365clientSecret}}
grant_type:client_credentials
scope:{{D365InstanceUrl}}/.default
tenant_id:{{G_AzureTenantId}}
This will use the variables you created earlier.
Create a Test
This is not really a test but a way to get the returned access token into the collection variable c_bearertoken, for use in other calls.
Add this code as a test:
if (pm.response.code == 200) {
pm.collectionVariables.set('c_bearertoken', pm.response.json().access_token)
}
Test your call
You are now ready to get a token. Click Send. You should receive a 200 OK and a response body like this:
{
"token_type": "Bearer",
"expires_in": 3599,
"ext_expires_in": 3599,
"access_token": "ey ... KMw"
}
If you want to, you can copy the access token and paste it into the windows at jwt.ms to get more information. The Roles array should contain the roles you assigned earlier. Please note that a token is only valid for one hour. After that you need to get a new one.
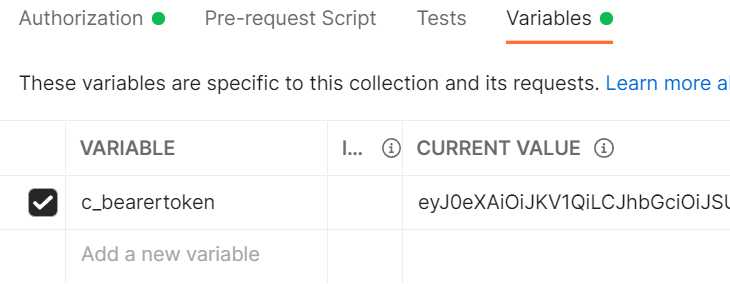
Verify that the collection variable c_bearertoken has been populated.
Calling and exploring the data APIs
These APIs can get information about, and to some extent manipulate data in your D365 instance. In my case I want to get the status of a given batch. This scenario will be covered in depth in another post.
To find in-depth information about the D365 data RestAPIs you can try to negotiate the official documentation. This is useful when you need to answer questions like “How to use enums in queries?”
I will use the so called OData endpoint.
Adding authorization to your call
This will be a collection wide setting. Update your collection according to:
Type: Bearer Token
Token: {{c_bearertoken}}
This will add your access token from earlier to all calls.
Construct a call
The basic enpoint is Your D365 Instance/data. In postman create a GET that uses this URL {{D365InstanceUrl}}/data.
Make sure the Authorization option is set to Inherit from parent.
Click send and receive a huuuuge list of all the data objects in your D365 instance.
Exploring the API
Where can I find batch jobs?
I needed to get information about the status of a batch job. In the response body I searched for the word batchjob:
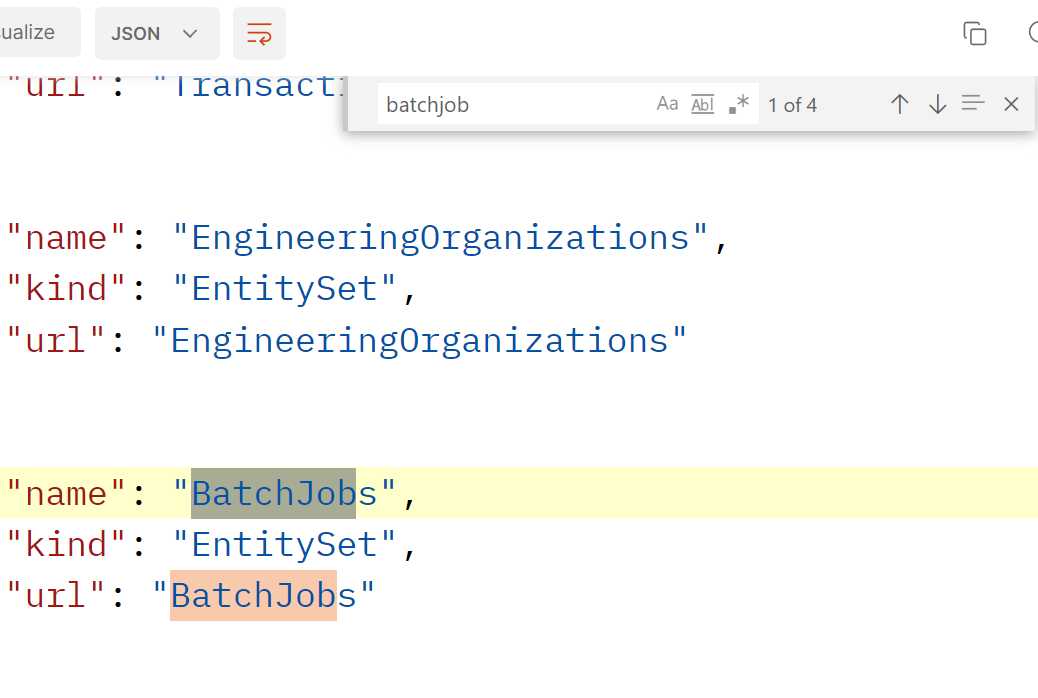
This tells me that there is a data object called BatchJobs. Add it to the URL of the call: {{D365InstanceUrl}}/data/BatchJobs.
VERY IMPORTANT!!! The data object name is case sensitive! {{D365InstanceUrl}}/data/batchjobs returns a 404.
There is a list of all the batch jobs!
The call to list the batch jobs took 15 seconds and the list is very long, but looking at each entity there is a Status field. This is what I need. Now, can I get the status of a single batch job?
Using $filter?
According to the documentation you can use all kinds of sorting and filtering, which is very good but also something I expect from an OData API.
If I want to find information on Batch Job 5637515827 I can filter for BatchJobRecId using standard API filter syntax.
Update the URL to {{D365InstanceUrl}}/data/BatchJobs?$filter=BatchJobRecId eq 5637515827. This will return an array with the specific ID.
More exploration
Now that you know how to do the basic things, like authenticating and navigating the APIs, you should be able to get all kinds of information about the state of your D365 instance.